时间:2025-09-18 20:49 / 来源:未知
从而识别新的样本mt4模拟交易平台策画机视觉全邦三大顶会之一的CVPR 2021论文吸收结果出炉!本次大会收到来自环球共7015篇有用投稿,最终有1663篇优秀重围被入选,任命率约为23.7%。本次,腾讯优图实践室共有20篇论文被收录,此中Oral论文4篇,涵盖人脸识别、抗衡攻击、时序行为定位、视频行为支解、无监视人脸质地评估等前沿范畴。
本论文已被CVPR 2021吸收为Oral论文。最新的考虑发明,球形空间能够更好地结婚人脸图像的根本几何形势,这一点一经正在目前最优秀的人脸识别办法中获得说明。然而,这些办法依赖于确定性的特点外达,以是会遭遇特点歧义性的外达困难。PFE是处置这一困难的初次考试。为了进一步处置PFE行使时的亏欠,咱们提出了一种用于球形空间中人脸置信度研习的新鲜框架。正在数学上,咱们将von Mises Fisher密度推论到其r半径对应项,并导出优化方针的闭式解。咱们从外面上解说,所提出的框架具有更好的可注解性,进一步推导出了特点调解与特点比对的数学外达式。正在众个具有寻事性的基准上通常的实践结果说明了咱们的假设和外面,并涌现了咱们的框架正在危急操纵的识别做事以及人脸验证和识别做事中相看待先前的概率办法和旧例球形确定性嵌入的优良本能。
本论文已被CVPR 2021吸收为Oral论文。非参数化的人脸修模旨正在不依赖几何假设的情景下从图像中重修3D人脸。尽量这类办法不妨预测必定的细节,但其方向于太过依赖局限颜色外观,且易受到噪声的滋扰。为收拾该题目,本文提出一种新的鸠集与特异化研习框架(LAP) 以完成无监视的3D人脸修模。该办法从无统制的人像集中中隐式的解耦ID划一和场景特异的人脸。完全地,为研习ID划一人脸,LAP基于一种新的带有浮松划一性耗费的课程研习办法,自适合地鸠集统一身份的本征人脸元素。为了使人脸适合于某一特异的场景,咱们提出了一个新的属性调动收集以运用方针属性和细节窜改ID划一人脸。基于本文的办法,使得无监视的3D人脸受益于居心义的人脸构造讯息和更高的诀别率。正在公然数据库上的洪量实践解说,与目前最优办法比拟,LAP能够重修更好的或有比赛力的人脸几何和纹理。
本论文已被CVPR2021吸收为Oral论文。近年来,图像到图像翻译正在完成众标签(以差别标签行动要求)和众气魄(天生众种样式的输出)做事中都博得了宏大起色。然而,因为未开荒标签中的独立性和排他性导致的翻译结果不行控导致了这些办法的退步。正在本文中,咱们提出了宗旨气魄解耦(HiSD)来处置此题目。完全来说,将标签从头陈列因素层的树状构造,从上到下递次是独立的标签,互斥的属性妥协耦的气魄。相应地,咱们计划了一种新的翻译进程来适合上述构造,将气魄与特定标签或属性对应起来,完成可控的翻译。CelebA-HQ数据集上的定性和定量结果都阐明了HiSD的技能。咱们心愿咱们的办法将行动宗旨气魄解耦的基准,助助来日的图像到图像翻译的考虑。
本论文已被CVPR2021吸收为Oral论文。批样板(BatchNorm,简称BN)一经被视为神经收集教练的默认组件之一,尽量BN是有益于安祥模子教练以及模子的合座外征技能,然而也不行避免地玩忽了教练数据个别之间的特点分歧。咱们提出了一个简易有用的特点校准战略用来巩固数据个别的特点外达技能,并险些不添加特地的耗时。咱们提出的这个核心校准办法能够巩固有用的特点讯息,而删除噪声特点。缩放校准方面,则不妨通过统制特点强度以研习获得一个越发安祥的特点分散。咱们将上述提出的BN变种办法,定名为Representative BN,这一办法不妨助助提拔众种策画机视觉做事的成效,如分类、检测和支解等。
本文提出了一种基于对照研习的新鲜对照正则化(CR)技巧,以应用笼统图像和明晰图像的讯息永诀行动负样本和正样本。CR确保正在暗示空间中将还原后的图像拉到更逼近明晰图像,并推到远离隐晦图像的位子。
别的,思量到本能和内存存储之间的量度,开荒了一个基于类主动编码器(AE)框架的紧凑型除雾收集,可永诀受益于自适合地保全讯息流和扩展吸收域以提升收集的转换技能。将具有主动编码器和对照正则化功用的除雾收集称为AECR-Net,正在合成和确凿数据集前进行的通常实践解说,咱们的AECR-Net超越了最新技巧。
近年来为了确保非受限场景的安祥性和牢靠性,人脸质地评估(Face Image Quality Assessment, FIQA)一经成为人脸识别编制不行或缺的一局部。这种办法只运用了类内讯息,而怠忽了类间讯息。正在本事情中,咱们以为高质地的人脸该当与其类内样本一致并与其他样本纷歧致,以是提出了一种新的无监视FIQA办法,该办法联结了一致分散间隔举办人脸图像质地评估(SDD-FIQA)。咱们通过策画正负样本一致度分散间的Wasserstein间隔天生高质地的伪标签,并以此教练用于质地预测的回归收集。实践结果解说,咱们提出的SDD-FIQA明显超出了SOTA办法。同时,咱们的办法正在差别的识别编制上显示出优良的泛化性。后续咱们将开源该事情。
人群偏向是本质人脸识别编制中的宏大寻事。现有办法主要依赖切确的人群标签,还不敷通用。于是,咱们提出了基于误报率处治的耗费函数,它通过添加实例误报率(FPR)的划一性来减轻人脸识别偏向。完全来说,咱们起初将实例FPR界说为高于团结阈值的非方针一致度数目与非方针一致度总数之间的比率。通过给定总FPR,能够忖度出团结阈值,然后将实例FPR与总FPR的比例处治项引入基于softmax的耗费函数分母中。实例FPR越大,处治越大。应用这种不屈等性的处治,使得实例FPR具有划一性。该办法不必要人群标签,并可减轻群体之间因种种属性划分的偏向,而这些属性正在教练中无需预先界说,正在主流实践基准上的通常测试结果解说,此办法已抵达了SOTA。
正在收拾抗衡样本时,深度神经收集显得至极敏锐,容易输出差池的预测结果。而正在黑盒攻击中,攻击者并不明白被攻击方针模子的内部构造和权重,以是教练一个取代模子去模仿方针模子内部构造即是一种至极高效的办法。
正在本文,咱们提出了一个全新的取代模子教练办法,即正在取代模子教练进程中引入更好的数据分散。起初是提出的众样性,越发众样性的教练数据分散能够获取越发丰饶的特点外述;其次,提出一个抗衡交换模子教练框架,将分散正在分界面的抗衡样本引入到取代模子教练进程中。通过联结两种思绪,能够进一步提拔取代模子和方针模子之间的一致性,从而提拔黑盒攻击的胜利率。实践结果解说,咱们的办法抵达了SOTA,相干的可视化结果也阐明了所提出办法的上风。
现有的深度研习去雾办法众采用单帧去雾数据集举办教练和评测,从而使得去雾收集只可应用目前有雾图像的讯息光复明晰图像。其它一方面,理念中的视频去雾算法却能够运用相邻的有雾帧来获取更众的时空冗余讯息,从而获得更好的去雾成效,但因为视频去雾数据集的缺失,视频去雾算法鲜有考虑。
为了完成视频去雾算法的监视教练,咱们初次提出了一组确凿的视频去雾数据集(REVIDE)。运用细心计划的视频采撷编制,胜利地正在统一场景举办两次采撷,从而同时记实下确凿全邦中成对且完满对齐的有雾和无雾视频。思量到获取有雾视频帧间时空冗余讯息的寻事性,咱们还计划了一个由置信度教导的矫正型可变形卷积收集(CG-IDN)来收拾有雾视频。实践阐明,REVIDE数据会合采撷的有雾场景远比合成雾更为挨近确凿场景,而且咱们提出的办法也优于现有的种种去雾算法。
时序行为定位正在视频判辨中如故是一个备受寻事的做事。该做事的目标是正在一个未剪辑且较长的视频中找到每个行为的肇始与完了工夫,以及改行为的分类结果。和预设锚框或者罗列分数的办法对照,无锚框的办法无需依赖少许冗余的超参数,显得更轻量。
以是,咱们提出了第一个高效高本能且完整无锚框的时序行为定位办法。模子搜罗:(1) 端到端可教练的底子预测器;(2) 基于明显性优化的模块,该模块通过一种新鲜的范围池化办法去为每个时序行为提名获取更有代价的范围特点;(3) 运用范围划一性统制来保障咱们的模子不妨找到精准的范围讯息。其它,正在THUMOS14数据集上,该办法比拟于之前基于锚框或运动分数指示的办法正在本能上有明显的提拔,正在ActivityNet v1.3数据集上也博得了最好的结果。
自监视研习通过从数据自己来获取监视信号,正在视频外征研习范畴暴露出了宏伟潜力。因为少许主流的办法容易受到配景讯息的诳骗和影响,为了减轻模子对配景讯息的依赖,咱们提出通过增加配景来去除配景影响。完全而言,给定一个视频,咱们从中随机采选一个静态帧,并将其增加到其它的每一帧中,以构修一个阔别当心力的视频样本,然后恳求模子拉近 阔别当心力的视频样本与原始视频样本之间的特点间隔,如斯使得模子不妨更好地抵当配景的影响,而更众地合怀运动蜕化。咱们的办法定名为配景排斥(Background Erasing,BE)。值适合心的是,咱们的办法能够便捷地增加到大无数SOTA办法中。BE正在MoCo的底子上,对具有主要配景意睹的数据集UCF101和HMDB51,永诀带来了16.4%和19.1%的提拔,而对具有较小配景意睹的数据集Diving48数据集带来了14.5%的提拔。
家喻户晓,行人重识别(Person ReID)高度依赖于打扮纹理等视觉讯息。然而,本质行使中存正在众种纹理混杂的情景,这凌驾了大无数现有ReID办法的技能限制。以是,咱们提出应用人的三维形势和身段讯息来提升ReID对纹理混杂的鲁棒性,而不光依赖于图像纹理讯息。现有的person ReID运用的形势研习模子要么怠忽了人确凿凿三维讯息,要么必要特地的物理摆设来采撷三维源数据。正在本文中,咱们提出了一种新鲜的研习框架,即联结三维形势研习(3DSL)模子: 参预三维人体重修行动正则化,直接从二维图像中提取纹理不敏锐的3D模子编码讯息。基于正则化的三维重修迫使ReID模子将三维形势讯息从视觉纹理中解耦,得回具有判别性的三维形势ReID特点。为领悟决缺乏三维ground truth的题目,咱们提出了一种抗衡式自我监视投影(ASSP)办法以拟合不必要ground truth监视教练的三维重修模块。正在通用ReID数据集和纹理混杂数据集上的洪量实践验证了咱们模子的有用性。
因为仅运用分类做事对方针举办定位的亏欠,弱监视方针定位(WSOL)如故存正在少许寻事。已有的事情时时应用空间正则化战略提升方针定位精度,但往往怠忽了奈何从教练好的分类收集中提取方针构造讯息。
本文提出了一种两阶段的办法,称为构造依旧激活(SPA),以充实应用WSOL卷积特点中包括的构造讯息。正在第一阶段,计划了受限激活模块(RAM)来缓解由分类收集惹起的构造缺失题目。该模块基于张望:无统制的分类激活图和全部均匀池化层导致收集仅合精明标的局限区域。正在第二阶段,提出了一种称为自相干图天生(SCG)模块的后收拾办法,基于第一阶段获取的激活图得回构造依旧的定位图。完全地,咱们应用高阶自相干(HSC)提取保存正在模子中的固有构造讯息,之后鸠集众个位子的HSC获得准确的方针定位结果。正在搜罗CUB-200-2011和ILSVRC正在内的两个公然基准前进行的洪量实践解说,与基准办法比拟,本文提出的SPA办法博得了明显的本能提拔。
RSTNet: 基于可分别视觉词和非视觉词的自适合该心力机制的图像描绘天生模子
本文提出了一个视觉讯息巩固和众模态讯息敏锐的Transformer构造,应用网格与网格之间相对位子的几何相干处置了特点展平操作酿成的空间讯息耗费的题目,而且应用一个特地确当心力层怀抱视觉特点与语义特点的功绩,从而充实教导图像描绘中视觉词和非视觉词的天生,正在该做事的线上线下公然数据集上均阐明了此模子的上风。
全景支解旨正在将图像永诀支解为物体种别的方针实例和物质种别的语义实质。这种繁复的全场景解析做事必要腾贵的实例级和像素级评释来举办模子教练。迄今为止,仅用图像级标签研习的基于弱监视研习的全景支解(WSPS)仍未被物色。
本文为弱监视全景支解提出了一个有用的撮合物体与物质发现(Jointly Thing-and-Stuff Mining, JTSM)框架,昭着地推理了方针前景和物质配景之间的语义和共现相干。为此,算法计划了一种新鲜的感有趣掩模池化(Mask of Interest Pooling, MoIPool),用于提取纵情形势支解的固定尺寸的像素准确特点图。MoIPool使全景发现分支不妨应用众实例研习(Multiple Instance Learning, MIL),并以团结的办法识别物体和物质。算法引入并行实例和语义支解分支,通过自教练进一步订正的支解掩模,其让从全景发现中发现的掩模和以自底向上的方针线索合作天生伪确凿标签,以提升空间划一性和轮廓定位。
咱们心愿为语义支解办法供给另一种思绪,将语义支解改动为序列到序列的预测做事。正在本文中,咱们运用transformer(不运用卷积和低落诀别率)将图像编码为一系列patch序列。transformer的每一层都举办了全部的上下文修模,联结旧例的Decoder模块,咱们获得了一个健旺的语义支解模子,称之为Segmentation transformer(SETR)。洪量实践解说,SETR正在ADE20K(50.28%mIoU),Pascal Context(55.83%mIoU)上抵达SOTA,并正在Cityscapes上博得了较好结果。
小样本研习(FSL)旨正在通过应用极为有限的援手集样原本适合所学常识,从而识别新的样本,是策画机视觉中的一个首要绽放题目。小样本研习顶用于特点对齐的大无数现有办法仅思量图像级或空间级对齐,而怠忽了通道分歧。
正在本文,咱们提出了一种动态对齐办法,可遵照差别的当地援手讯息有用地优秀显示盘查区域和渠道。完全而言,这是通过起初动态采样以输入的少量镜头为要求的特点位子的邻域来完成的,基于此,咱们能够进一步预测依赖于位子和依赖于通道的动态元滤波器用于将盘查功用与特定于位子和特定于通道的常识对齐。别的,咱们采用神经收集常微分方程(Neural ODE)来完成更准确的对齐操纵。通过上述办法,咱们的模子不妨更好地拘捕援手集样本的的细粒度上下文语义。
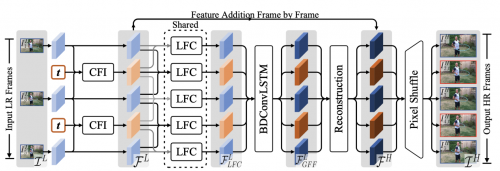
正在本文,咱们提出了一种称之为TMNet的工夫修模收集,该模子不妨对视频中心帧纵情插值高诀别率帧。完全而言,咱们提出了TMB模块用以调整可变形卷积效率正在可控特点插值中。为了更好的发现工夫讯息,咱们还提出了一个基于局限特点比对的LFC模块,该模块与双向可变形ConvLSTM模块一同效率,用以提取视频中的短时和长时运动讯息。正在3个威望规范数据集上咱们提出的办法都比过去STVSR办法正在恶果和成效上都要越发好,文中的融解实践比对进一步验证了咱们革新点的功绩。
为了解答“是否能够通过高效地查找差别感应野的之间的组合来取代手工计划的形式呢?”的题目,正在本文中,咱们提出一种基于从全部到局限的查找战略来寻找更符合的感应野组合。完全而言,咱们的查找战略将应用全部查找的上风来找到粗粒度的参数组合,然后正在应用局限查找来灵巧化感应野的组合形式。值得指出的是,全部查找并非是通过手工计划形式来寻找潜正在的粗粒度参数组合。正在全部查找的底子上,咱们将会运用一种基于祈望教导迭代的办法来有用地精修参数组合。结果,咱们的这一结果能够即插即用地运用正在目前行为支解的模子中,并博得了SOTA的成效。很速咱们也将开源咱们的代码完成。
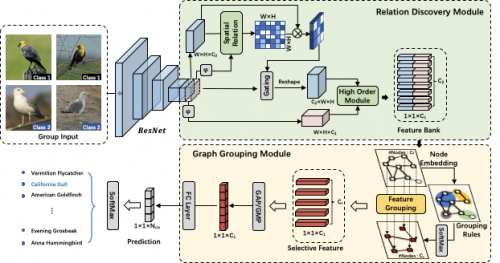
细粒度识其它厉重目标是通过研习种别间分别性特点外达来诀别外观高度一致对象,但大凡情景下,现有的大无数事情正在配景繁复下成效担心祥,且怠忽了差别语义特点之间的内正在干系。对此,咱们提出一种高效的基于图的相干发现办法来构修高阶相干间的上下文判辨。该办法起初通过特点间语义和位子感知来构修高维特点库(feature bank),同时举办正则化统制。其次本文提出一种基于图的语义分组办法(graph grouping),将高维特点照射到低维空间中,保存此中高分别性特点。正在教练进程中,本文还提出一种分组研习战略(group-wise learning),对特点聚类核心举办统制。通过以上三个模块的合作,该办法可研习到细粒度种别间更丰饶的分别性讯息。实践结果解说,该办法正在4个细粒度数据集上均超出SOTA。
CVPR 行动策画机视觉范畴的顶会之一,每年入选的论文险些都代外了本年度策画机视觉范畴最新、最高科研秤谌以及来日开展趋向。
此次入选了20篇论文,也是对腾讯优图实践室现阶段科研及革新技能的一种认同。来日,优图将连接勤恳,为行家带来更众或许的“视”界。
上一篇:网友发现自家酒精发霉ecn协议
下一篇:啊啊啊啊啊啊啊啊啊小白这个劲舞版刀马给我笑毁了…#白敬亭#不眠日#不眠日抖音追剧团#白敬亭劲舞版刀马刀马#白敬亭连刘海也在跳刀马刀马@DOU+上热门2025/9/18易遥购交易平台